لایه فعالسازی یک لایه در یک شبکه عصبی مصنوعی است که به خروجی یک لایه قبلی یک تابع اعمال میکند. این تابع معمولاً یک تابع غیرخطی است که به مدل اجازه میدهد تا ویژگیهای مهمی از دادهها را استخراج کند.اگر تو مدل های پایه دقت کنید بعد از یک کانولوشن حتما یک ReLU استفاده شده.
انواع توابع فعال سازی :
-
ReLU (Rectified Linear Unit)
-
Leaky ReLU
-
Sigmoid
-
Tanh
-
Softmax
تابع فعال سازی سیگموئید دارای مزایای متعددی از جمله موارد زیر است:
-
غیرخطی است که به شبکه های عصبی اجازه می دهد تا روابط پیچیده بین داده ها را بیاموزند.
-
مشتق پذیر است، به این معنی که می توان از آن در نزول گرادیان برای آموزش شبکه های عصبی استفاده کرد.
-
بین 0 و 1 محدود می شود که آن را برای مدل سازی احتمالات مناسب می کند
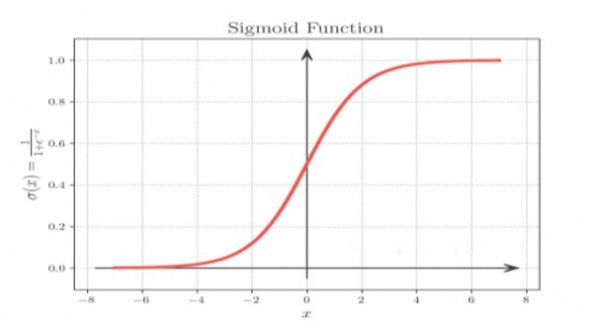
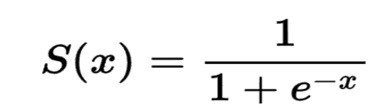
تابع فعال سازی tanh دارای مزایای متعددی از جمله موارد زیر است:
-
غیرخطی است که به شبکه های عصبی اجازه می دهد تا روابط پیچیده بین داده ها را بیاموزند.
-
مشتق پذیر است، به این معنی که می توان از آن در نزول گرادیان برای آموزش شبکه های عصبی استفاده کرد.
-
حول محور صفر متمرکز است که آن را برای کارهای رگرسیون مناسب می کند.
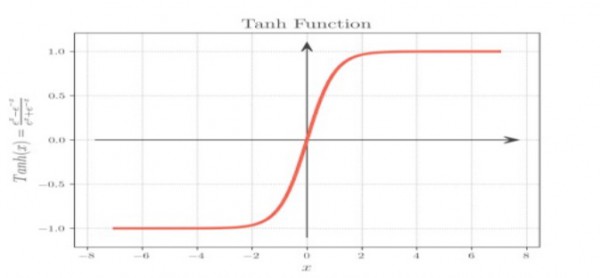
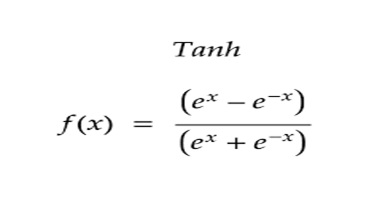
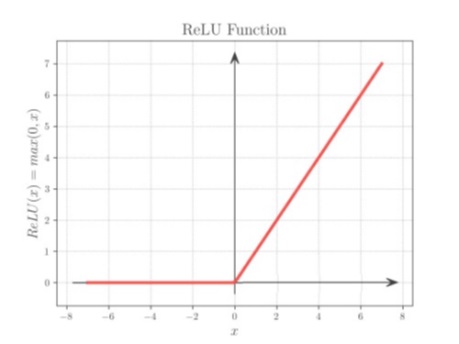
تابع فعال سازی ReLU (واحد خطی اصلاح شده):
یک تابع قطعه ای خطی است که اگر ورودی مثبت باشد، ورودی را به طور مستقیم خروجی می دهد، در غیر این صورت، صفر را خروجی
می دهد. این تابع به صورت زیر تعریف می شود:
f(x) = max(0, x)
تابع فعال سازی ReLU یکی از محبوب ترین توابع فعال سازی در یادگیری عمیق است.
زیرا آموزش آن سریع است و اغلب عملکرد بهتری نسبت به سایر توابع فعال سازی، مانند توابع سیگموئید و tanh، به دست
می آورد.
مزایای ReLU :
-
غیرخطی است که به شبکه های عصبی اجازه می دهد تا روابط پیچیده بین داده ها را بیاموزند.
-
مشتق پذیر است، به این معنی که می توان از آن در نزول گرادیان برای آموزش شبکه های عصبی استفاده کرد.
-
محاسبه آن سریع است که آن را برای شبکه های عصبی بزرگ مناسب می کند.
-
در مقایسه با سایر توابع فعال سازی، مانند توابع سیگموئید و tanh، کمتر مستعد مشکل محو شدن گرادیان است.
معایب ReLU :
-
می تواند به نورون های مرده منجر شود، که نورون هایی هستند که هرگز مقدار مثبتی را خروجی نمی دهند. این می تواند زمانی اتفاق بیفتد که ورودی به یک نورون همیشه منفی باشد.
-
می تواند به مقداردهی اولیه وزن های یک شبکه عصبی حساس باشد. اگر وزن ها خیلی کوچک مقداردهی اولیه شوند، نورون ها ممکن است هرگز مقدار مثبتی را خروجی ندهند.
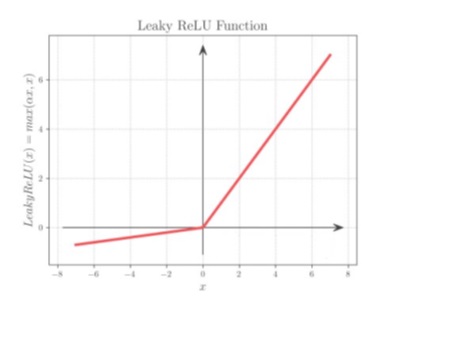
تابع فعال سازی leaky ReLU (واحد خطی اصلاح شده نشتی) :
یک نسخه اصلاح شده از تابع فعال سازی ReLU است. این تابع به صورت زیر تعریف
می شود:
f(x) = max(α * x, x)
که در آن α یک مقدار مثبت کوچک است، معمولاً بین 0.01 و 0.1.
تابع فعال سازی leaky ReLU شبیه به تابع فعال سازی ReLU است، با این تفاوت که برای ورودی های منفی، یک مقدار مثبت کوچک خروجی می دهد. این به جلوگیری از مشکل نورون های مرده کمک می کند.
نورون هایی هستند که هرگز فعال نمی شوند زیرا ورودی های آنها همیشه منفی است.
مزایای leaky ReLU :
-
کمتر مستعد مشکل نورون مرده است.
-
آموزش آن پایدارتر است.
-
در برخی از وظایف، مانند طبقه بندی تصویر و پردازش زبان طبیعی، عملکرد بهتری داشته است.
معایب leaky ReLU :
-
محاسبه آن کمی کندتر از تابع فعال سازی ReLU است.
-
برای تنظیم شدن نیاز به یک پارامتر اضافی، α، دارد.