در واقع overffiting باعث خرابی در generalization شبکه میشه.
فرض کنید ما یک سری داده یا نقاط به عنوان داده های آموزشی داریم که قصد داریم با یک منحنی آن را به دو گروه دسته بندی کنیم.
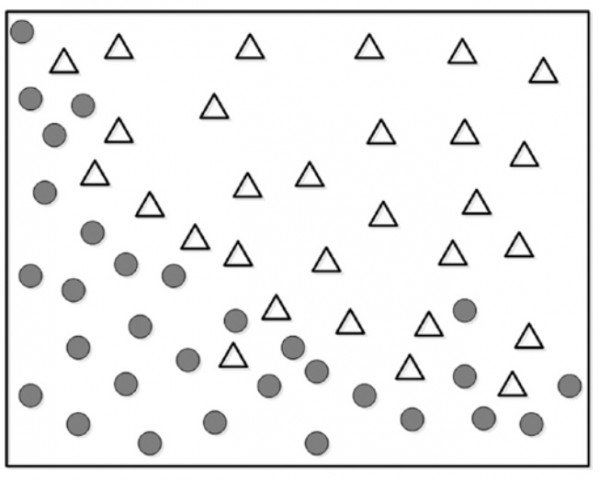
اگر بخایم یک منحنی منطقی جهت دسته بندی کردن این دو گروه از داده به صورت زیر میشه هر چند که برخی از نقاط خارج گروه خودشان قرار گرفته اند.
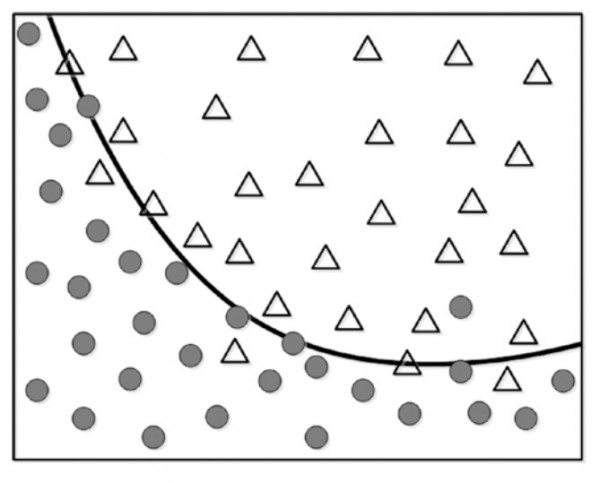
از آنجایی که برخی از نقاط توی گروه خودشان قرار نگرفتند اند می تونیم چنان دقیق دسته بندی کنیم که همه داده در گروه صیحیح خود قرار بگیرند همانند شکل زیر :
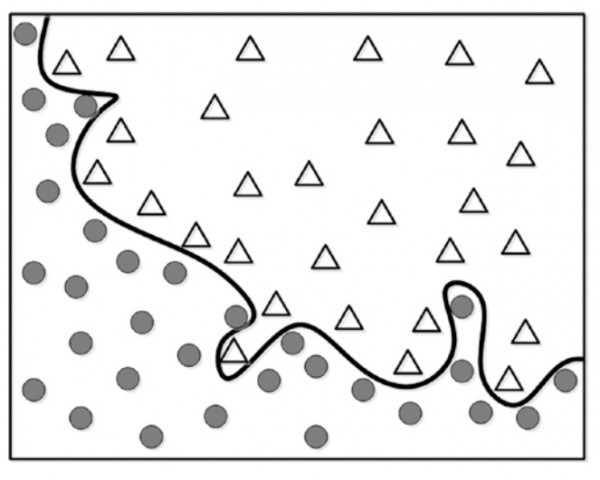
این مدل دومی به صورت دقیق داده ها را دسته بندی می کنه به نظر شما این از مدل اول بهتر عمل می کنه؟
حال فرض کنید ما یک نقطه جدید داریم که با مربع مشکی توپر نشان دادیم و تصمیم داریم با همین مدل دوم که دقیقه این نقطه جدید را دسته بندی کنیم.
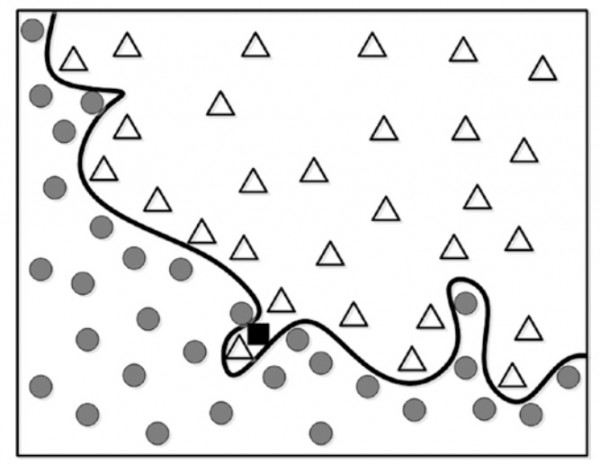
قاعدتاً مدل دقیق میگه این داده جدید باید در کلاس مثلث قرار بگیره ولی اگر منطقی به قضیه نگاه کنیم این داده جدید جز دسته گروه دایره ها است.
اینکه بعضی از نقاط متعلق به یک گروه در دل گروه دیگه قرار گرفتن اینها در واقع همان داده های نویزی هستند و یادگیری ماشین راهی جهت جدا کردن دقیق این نقاط نداره.در واقع کلاسیفایر ما به کلیت داده های ما نگاه می کنه و سپس مرز دسته بندی یا همان منحنی در این مسئله را برای ما محاسبه می کنه.شما باید این نکته را در نظر داشته باشید که همیشه این نویز ها وجود ندارند و شبکه باید طوری دسته بندی را انجام بده که شبکه ما قابلت تعمیم پذیری داشته باشه.اگر شما مدلی داشته باشید که قدرت تعمیم پذیریش کم باشه اصطلاحا بهش می گن که مدل شما overfit شده.
تو یادگیری عمیق هم برای جلوگیری از overfitting شبکه از تکنیک dropout و regularization و Data augmentation استفاده می کنند.